Utilisation du module Pandas⚓︎
Le module csv utilisé précédemment se contente de lire les données structurées. Il ne fait aucun effort particulier pour analyser les données. Par exemple les valeurs décimales sont interprétées comme des chaînes de caractères.
La bibliothèque pandas est par contre spécialement conçue pour l'analyse des données (data analysis) : elle est donc naturellement bien plus performante.
Lien vers la documentation de la librairie PANDAS (en anglais) : documentation
Nous reprenons notre fichier de joueurs de rugby du Top14.
🔽 Télécharger le notebook de cours correspondant ici
import pandas as pd #import du module pandas, abrégé classiquement par "pd"
df = pd.read_csv('top14.csv', encoding = 'utf-8')
La variable est nommée classiquement df pour dataframe (que l'on peut traduire par table de données)
type(df)
>>> pandas.core.frame.DataFrame
Premiers renseignements sur les fichiers de données⚓︎
❓ Que contient la variable df?
réponse
Les données sont présentées dans l'ordre originel du fichier.
Il est possible d'avoir uniquement les premières lignes du fichier avec la commande head() et les dernières du fichier avec la commande tail(). Ces commandes peuvent recevoir en paramètre un nombre entier.
❓ Que fait l'instruction df.head() ?
réponse
df.head()
Df. Par défaut n=5.
❓ Que fait l'instruction df.tail() ?
réponse
df.tail()
Df. Par défaut n=5.
❓ Que fait l'instruction df.head(3) ?
réponse
df.head(3)
Df.
Pour avoir des renseignements globaux sur la structure de notre fichier, on peut utiliser la commande df.info()
df.info()
>>> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 595 entries, 0 to 594
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Equipe 595 non-null object
1 Nom 595 non-null object
2 Poste 595 non-null object
3 Date de naissance 595 non-null object
4 Taille 595 non-null int64
5 Poids 595 non-null int64
dtypes: int64(2), object(4)
memory usage: 28.0+ KB
Pour accéder à une fiche particulière de joueur, on peut utiliser la fonction df.loc() :
df.loc[45]
>>> Equipe Bayonne
Nom Torsten VAN JAARSVELD
Poste Talonneur
Date de naissance 30/06/1987
Taille 175
Poids 106
Name: 45, dtype: object
Extraction de colonnes, création de graphiques⚓︎
Pour créer une liste contenant uniquement les données numériques de la colonne poids, il suffit d'écrire :
poids = df['Poids']
⚠️ Attention, la variable poids n'est pas une liste qui contiendrait [122,116,112,...] mais un type particulier à pandas, appelé Series.
print(poids)
0 122
1 116
2 112
3 123
4 119
...
590 78
591 97
592 91
593 85
594 86
Name: Poids, Length: 595, dtype: int64
```
```python
type(poids)
>>> pandas.core.series.Series
On peut néanmoins s'en servir comme d'une liste classique.
poids[0]
>>> 122
On voit donc que les données sont automatiquement traitées comme des nombres. Pas besoin de conversion comme avec le module csv !
Pour tracer notre nuage de points poids-taille, le code sera donc simplement :
import matplotlib.pyplot as plt
X = df['Poids']
Y = df['Taille']
plt.plot(X,Y,'ro') # r pour red, o pour un cercle. voir https://matplotlib.org/api/markers_api.html
plt.show()
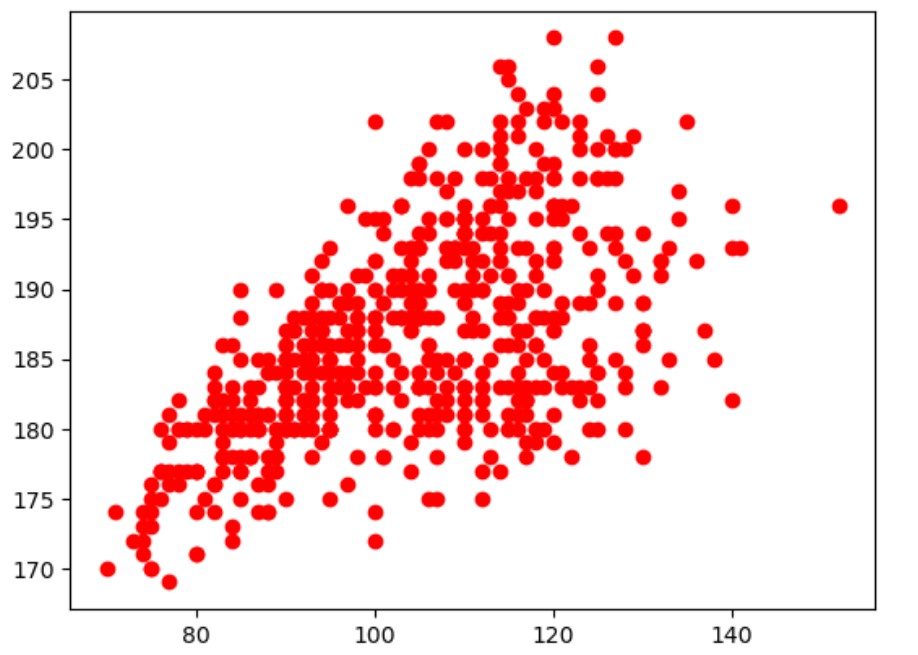
L'interprétation numérique permet à pandas d'analyser automatiquement les données, avec notamment la fonction df.describe().
df['Taille'].describe()
>>> count 595.000000
mean 186.559664
std 7.572615
min 169.000000
25% 181.000000
50% 186.000000
75% 192.000000
max 208.000000
Name: Taille, dtype: float64
Pour les données non-numériques, la commande describe() n'est que peu d'utilité. Elle renseigne toutefois la valeur la plus fréquente (en statistiques, le mode ou valeur modale)
Par exemple :
df['Poste'].describe().top
>>> '3ème ligne'
Le poste le plus fréquent est donc celui de '3ème ligne'.
Pour connaître par exemple la date de naissance la plus fréquente chez les joueurs du top14, on utilisera simplement :
❓ Quelle est la date de naissance la plus fréquente ?
réponse
df['Date de naissance'].describe().top
print(df['Nom'][df['Date de naissance'] == '23/04/1993'])
❓ Quels sont les joueurs les plus grands du TOP14 ?
réponse
df['Taille'].describe().max
print(df['Nom'][df['Taille']==208])
❓ Quel est le nombre de joueurs de Toulon ?
réponse
T = df[df['Equipe'] == 'Toulon']
T.describe()
Beaucoup plus de renseignements sont donnés par la commande value_counts().
df['Taille'].value_counts()
>>> 180 52
183 40
188 35
185 31
181 31
...
208 2
205 1
169 1
Name: Taille, dtype: int64
Filtres et recherches⚓︎
Comment créer une dataframe ne contenant que les joueurs de l'UBB ?
L'idée syntaxique est d'écrire à l'intérieur de df[] le test qui permettra le filtrage.
UBB = df[df['Equipe'] == 'Bordeaux']
>>> UBB
❓ Créer une dataframe poidsLourd qui contient les joueurs de plus de 135 kg.
réponse
poidsLourd = df[df['Poids'] > 135]
❓ Créer une dataframe grand_lourd qui contient les joueurs de plus de 2m et plus de 120 kg.
réponse
grand_lourd = df[(df['Poids'] > 120) & (df['Taille'] > 200)]
❓ Trouver en une seule ligne le joueur le plus léger du Top14.
réponse
df['Nom'][df['Poids'] == min(df['Poids'])]
print(df['Nom'][df['Poids'].idxmin])
Tris de données⚓︎
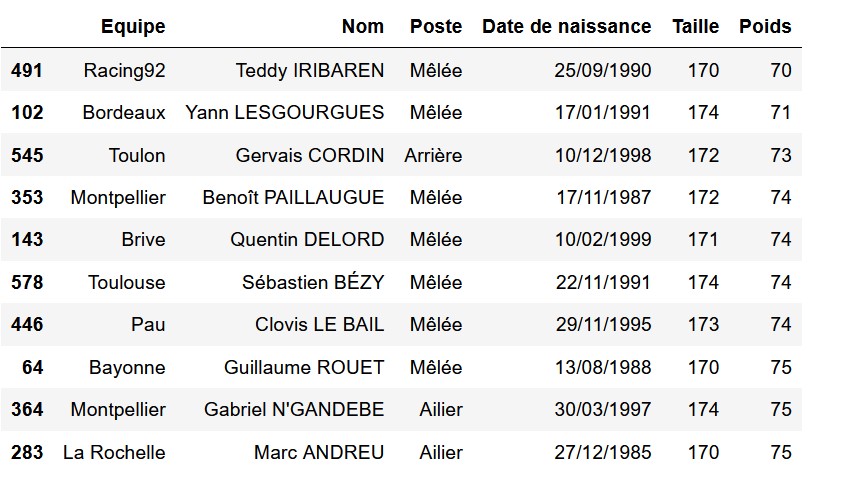
Le tri se fait par la fonction sort_values() :
newdf = df.sort_values(by=['Poids'], ascending = True)
newdf.head(10)
Ajout d'une colonne⚓︎
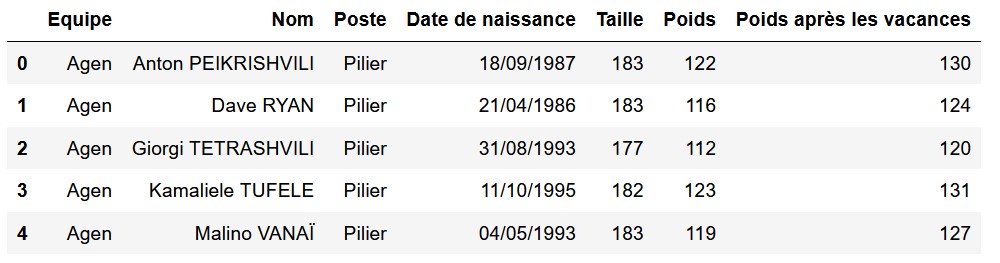
Afin de pouvoir trier les joueurs suivant de nouveaux critères, nous allons rajouter un champ pour chaque joueur.
Prenons un exemple stupide : fabriquons un nouveau champ 'Poids après les vacances' qui contiendra le poids des joueurs augmenté de 8 kg.
Ceci se fera simplement par :
df['Poids après les vacances'] = df['Poids'] + 8
df.head()
Pour supprimer cette colonne sans intérêt :
del df['Poids après les vacances']
df.head()
Exercice
- Créer une colonne contenant l'IMC de chaque joueur
- Créer une nouvelle dataframe contenant tous les joueurs du top14 classés par ordre d'IMC croissant.
df['IMC'] = df['Poids'] / (df['Taille']/100)**2
df.head()
imcdf = df.sort_values(by=['IMC'], ascending = True)